This paper addresses the problem of generating 3D interactive human motion from text. Given a textual description depicting the actions of different body parts in contact with objects, we synthesize sequences of 3D body poses that are visually natural and physically plausible. Yet, this task poses a significant challenge due to the inadequate consideration of interactions by physical contacts in both motion and textual descriptions, leading to unnatural and implausible sequences. To tackle this challenge, we create a novel dataset named RICH-CAT, representing ``\textbf{C}ontact-\textbf{A}ware \textbf{T}exts'' constructed from the RICH dataset. RICH-CAT comprises high-quality motion, accurate human-object contact labels, and detailed textual descriptions, encompassing over 8,500 motion-text pairs across 26 indoor/outdoor actions. Leveraging RICH-CAT, we propose a novel approach named CATMO for text-driven interactive human motion synthesis that explicitly integrates human body contacts as evidence. We employ two VQ-VAE models to encode motion and body contact sequences into distinct yet complementary latent spaces and an intertwined GPT for generating human motions and contacts in a mutually conditioned manner. Additionally, we introduce a pre-trained text encoder to learn textual embeddings that better discriminate among various contact types, allowing for more precise control over synthesized motions and contacts. Our experiments demonstrate the superior performance of our approach compared to existing text-to-motion methods, producing stable, contact-aware motion sequences.
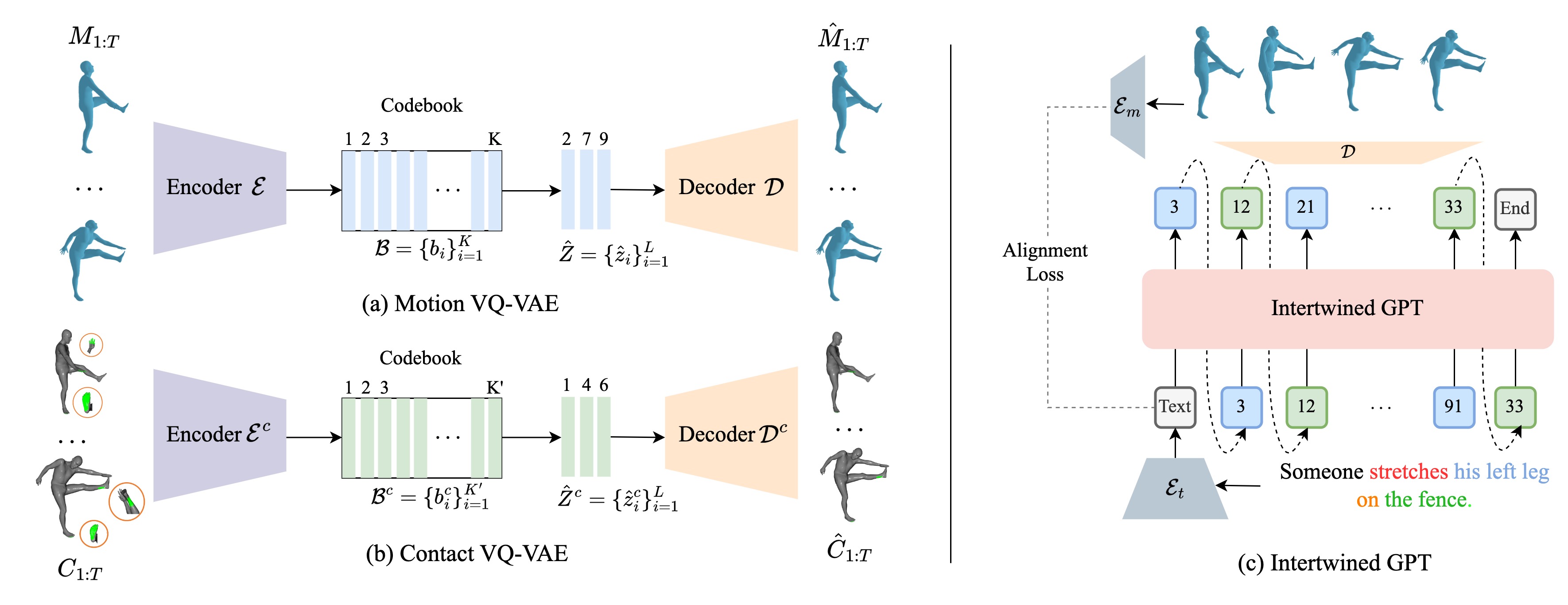
Our model consists of independent (a) Motion VQ-VAE and (b) Contact VQ-VAE to encode the motion and contact modalities into distinct latent spaces. Subsequently, we autoregressively predict a distribution of motion and contact from the text via (c) the intertwined GPT to explicitly incorporate contact into motion generation. The output from the intertwined GPT is then fed into the learned Motion VQ-VAE decoder to yield a sequence of 3D poses with physically plausible interactions. Additionally, the text embedding is extracted from our pretrained text encoder, with an alignment loss ensuring the consistency between interactive text embeddings and the generated poses. E_m is the movement encoder pretrained with the text encoder E_t to calculate the alignment loss.
@article{ma2024richcat,
author = {Ma, Sihan and Cao, Qiong and Zhang, Jing and Tao, Dacheng},
title = {Contact-aware Human Motion Generation from Textual Descriptions},
journal = {arXiv preprint arXiv:2403.15709},
year = {2024},
}